
HTMLにおける「代替」の意味について考えてみます。

代替テキストのマークアップ例
HTMLには画像に「代替テキスト」と呼ばれる値を設定する機能があります。
ユーザーがもし画像を利用できない状況にあるとき、画像の代わりにこの代替テキストが提供されます。

画像のパスが間違っていたり、ページの読み込みが途中で中断されてしまったりしてデータをうまく読み込めない場面はたまにあります。そういったとき、この代替テキストの値が画像の代わりに表示されます。
通信状況が悪いときや、画像が表示されないまま長い間更新されなくなったサイトを閲覧しているときでも、適切な代替テキストが設定されていれば最低限の情報は得られます。

支援技術を利用してサイトを閲覧しているユーザーにもこの代替テキストが提供されます。
支援技術というのは、主に障害者がパソコン利用の際に、操作の補助を行うために併用されるハードウェアとかソフトウェアです。
支援技術のひとつであるスクリーンリーダーを利用すると、画面上の情報をコンピュータに読み上げさせることができて、HTMLの画像にフォーカスすると代替テキストの値が読み上げられます。
スクリーンリーダーは全盲のユーザーやロービジョンのユーザーによく利用されます。

ところで「代替」という言葉はあまり耳慣れないかもしれません。辞書的な意味の定義はそれに見合う他のもので代えること。
であるそうです。
支援技術の話と関連して、アクセシビリティの文脈ではこの「代替」をどのように考えるかの議論が常にあり、何をもって代替とするかが永遠のテーマです。

代替テキストの書き方についてHTMLの仕様書では、すべての画像をその画像の
とあります。alt属性のテキストと置換してもページの意味を変えないことを意図する。

続いて、代替テキストは、もし画像を含めることができなかったならば、何が書かれていただろうかを考慮することで記述することができる。
と。
つまりこれは、仮にページ内のすべての画像が代替テキストに置き換わったとしても、ページがテキストのみのインターフェースとして成立するように代替テキストを記述すべしというわけです。

たとえばいわゆるハンバーガーボタンの代替テキストでは、アイコンの見た目について記述しようとすると「ハンバーガーボタン」とか「3本の横線」のような表現が思い浮かびます。ですがテキストとして画像の目的を表現すると考えると、ハンバーガーボタンはメニューを開くボタンなので代替テキストは「メニュー」になります。

プラス記号のアイコンではどうでしょうか。これもアイコンだけを見て考えると「プラス」のような表現になりそうなところですが、ハンバーガーボタンのように機能に着目して考えると、このアイコンはデータを追加するボタンに使われると仮定して「追加」がよさそうです。

ペンのアイコンではどうでしょう。これも機能について考えると「編集」辺りでしょうか。

それでは、これまでのアイコンとは違って「海の写真」を掲載する場合にはどうすればよいでしょうか。
これまでアイコンの代替テキストを記述する際には、アイコン自体の見え方よりもアイコンを利用した目的に着目していました。実は代替テキストは画像だけでなく、その画像がどのような文脈で使用されているかを知らなければ考えられません。
代替テキストにおいてはむしろ、画像自体の見た目よりも、サイトの提供者が画像を利用した目的や画像に期待する機能を表現します。
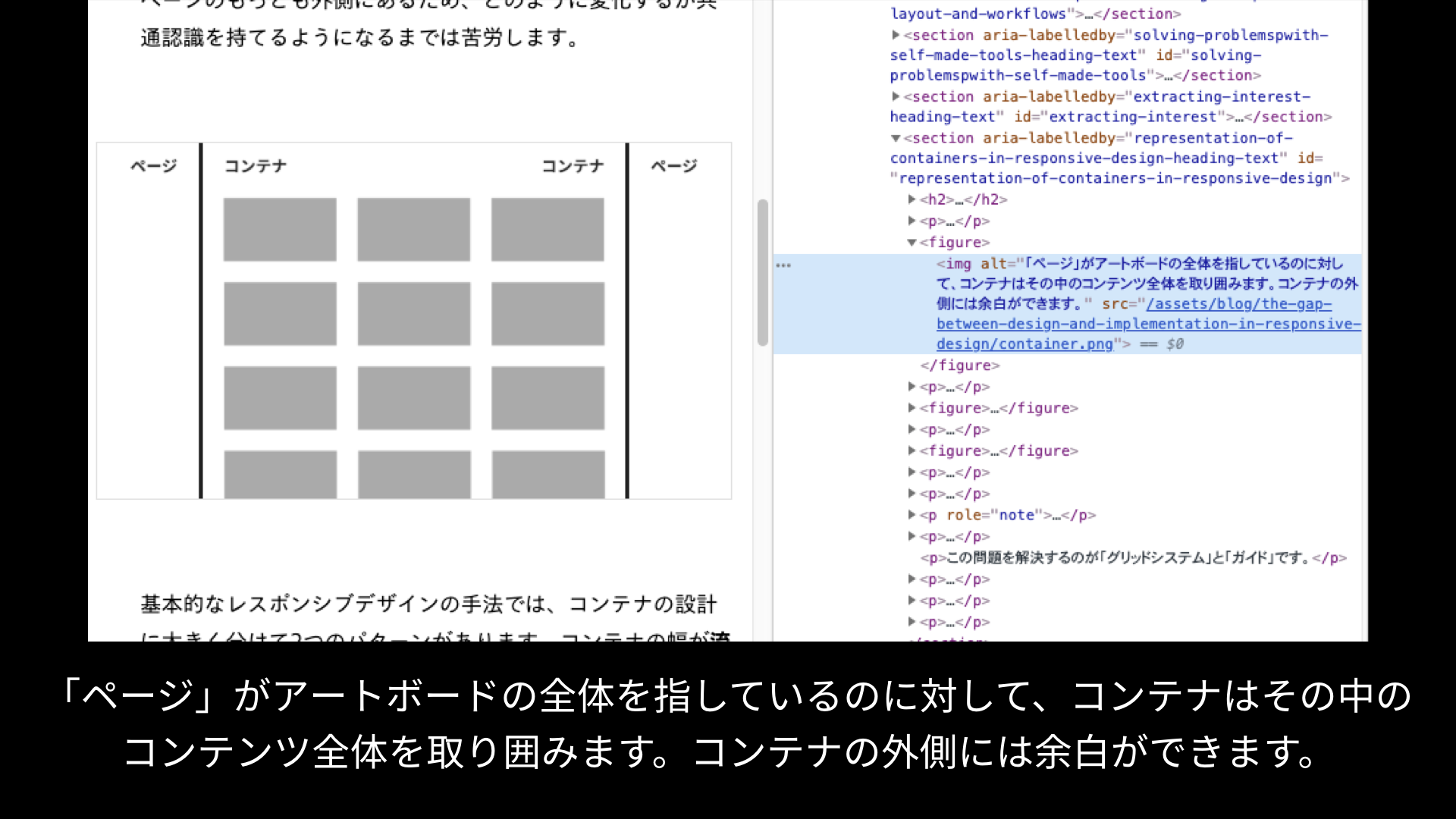
最近私がブログ記事に掲載した画像には代替テキストとして、『ページ』がアートボード全体を指しているのに対して、コンテナはその中のコンテンツ全体を取り囲みます。コンテナの外側には余白ができます。
というほぼ記事の段落さながらな内容を設定しています。
これは記事中に登場する画像なので、その前後の文脈に沿ってこの画像に期待する機能を表現しています。そうすれば仮に画像が表示されなくても、画像の利用で意図した役割を代替テキストに担わせられます。
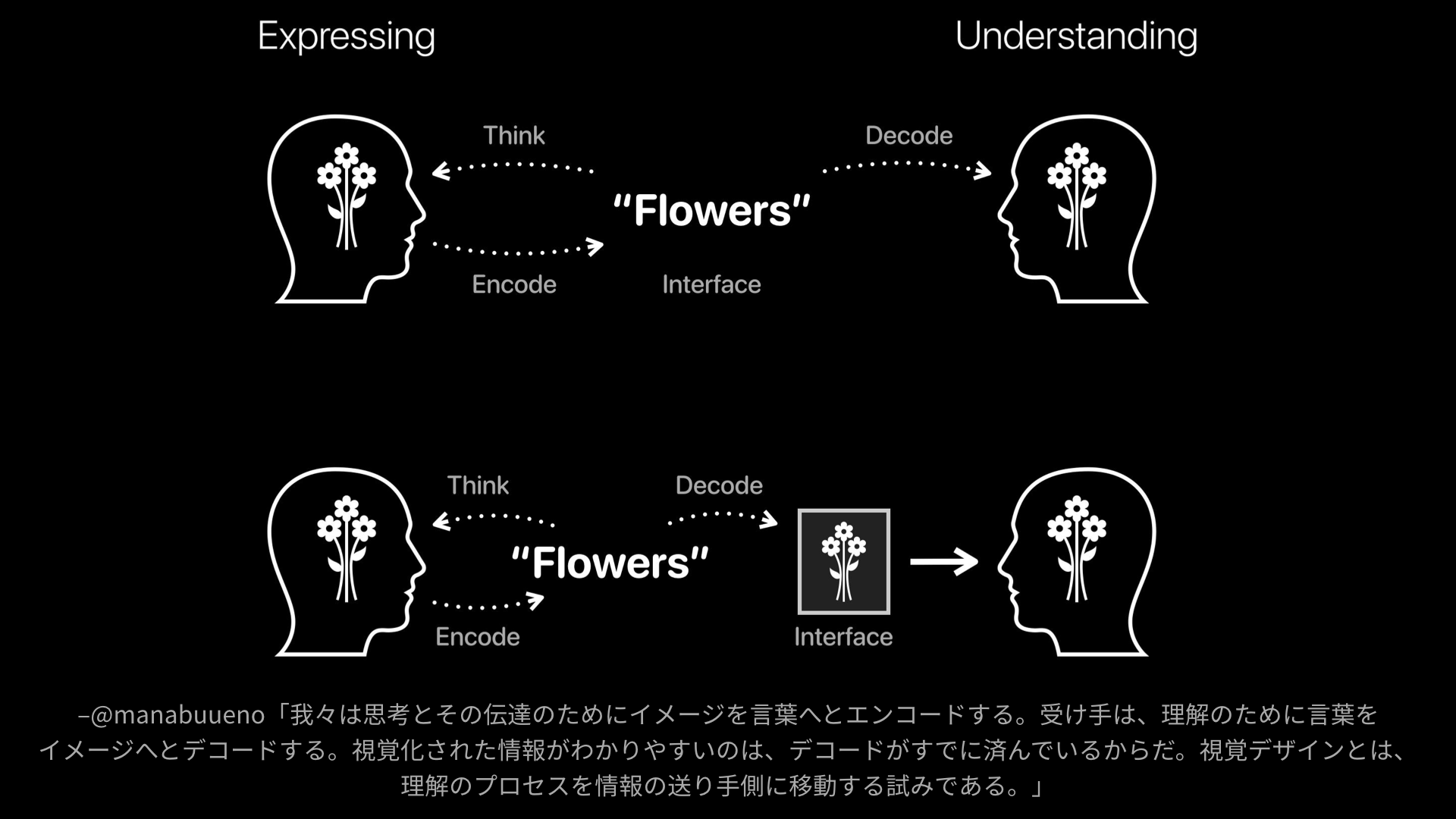
人と人とがコミュニケーションするとき、情報の発信者はまず受信者にとって知覚可能な何かしらの表現をしています。発信者の頭の中にある考えをそのまま受信者の頭の中にも複製するようなことはできませんから、前提としてお互いに認識できる形に起こす必要があります。
日本語や英語のような自然言語によるコミュニケーションでは、受信者は、発信者が形にした言葉を手掛かりにして対応するイメージへ変換する作業を行なっています。
一方で自然言語でなく視覚化された情報の場合、人の理解の形に近いイメージがそのまま表現されているため、受信者の理解の負担が軽減されます。
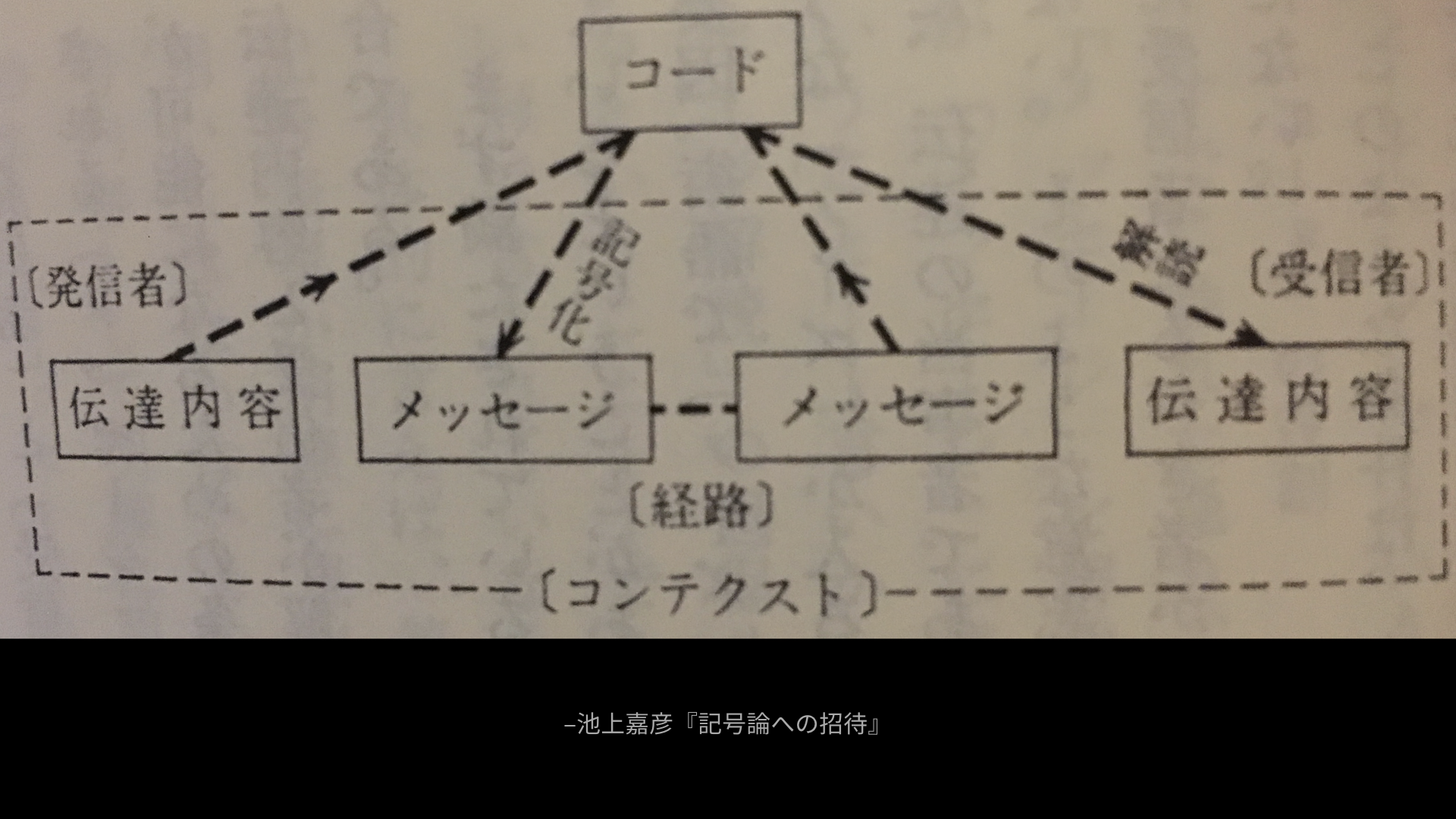
「コード」は言語における「辞書」や「文法」のようなもの
『記号論への招待』によれば、発信者は「伝達内容」をお互いの共通認識に沿った形式を意識しながら知覚可能な「メッセージ」に変換し、受信者はその「メッセージ」の解読によって発信者の「伝達内容」にたどり着きます。
画像および代替テキストはこの中の「メッセージ」に位置付けられます。そしてHTMLの仕様に基づけば、画像およびその画像に対応する代替テキストは、メッセージとしての形は違えど共通の「伝達内容」を伝えるものです。
このメッセージをもう少し馴染みのある言葉に置き換えてみると「インターフェース」であり、つまり代替テキストは画像の「代替インターフェース」であるとも言えます。
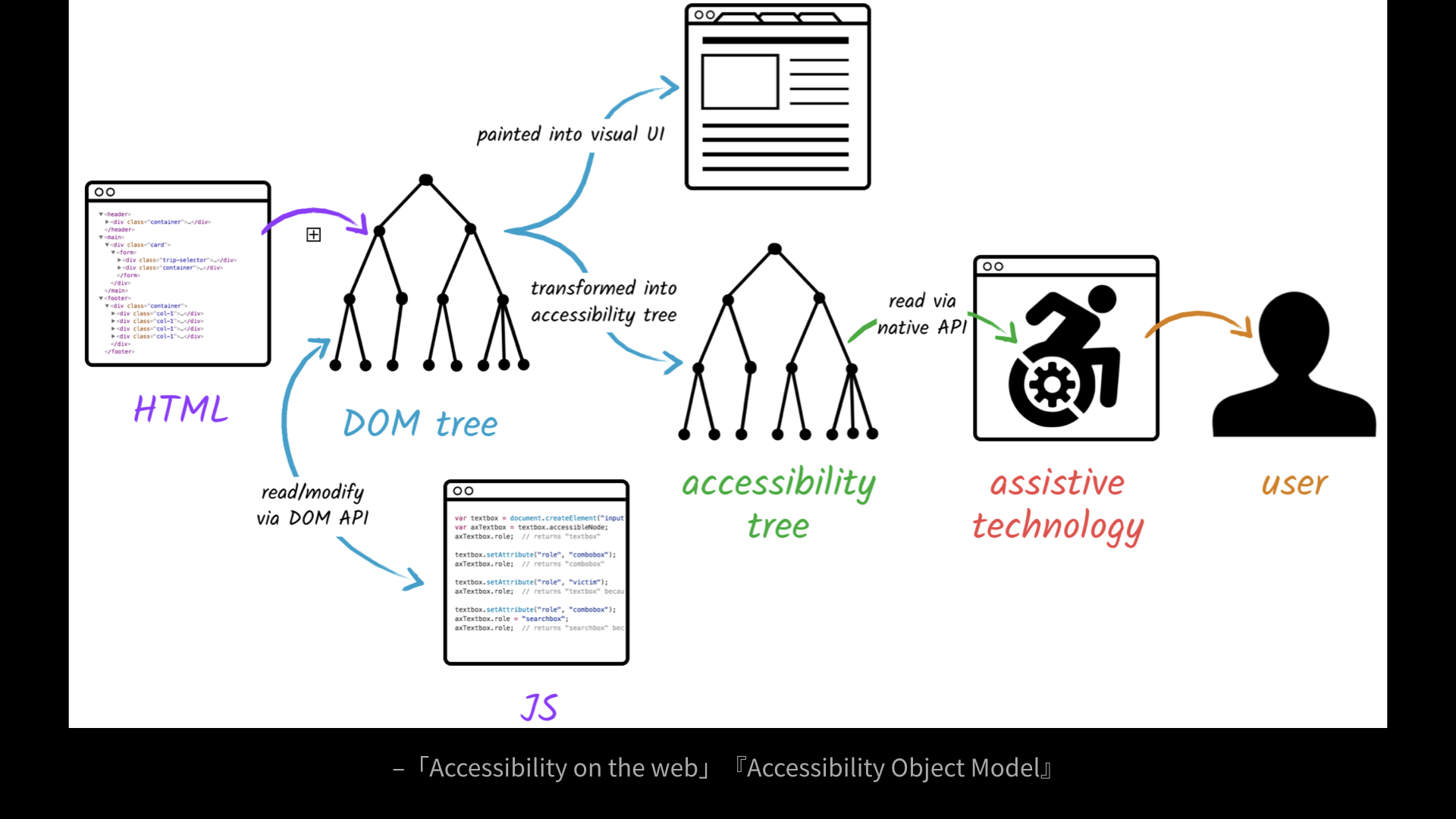
アクセシビリティにおいては、実はこの「代替」の発想が画像だけに限らずHTMLのページ全体に適用されています。
ブラウザは目に見える画面を描画する前にHTMLをDOMツリーに変換していますが、同時にそのDOMツリーから「アクセシビリティツリー」と呼ばれるものの構築も行なっています。
スクリーンリーダーなどの支援技術は、プラットフォームが提供する「アクセシビリティAPI」を介してこのアクセシビリティツリーとやり取りします。
支援技術のユーザーにとってはこのアクセシビリティツリーこそがインターフェースだと言えます。
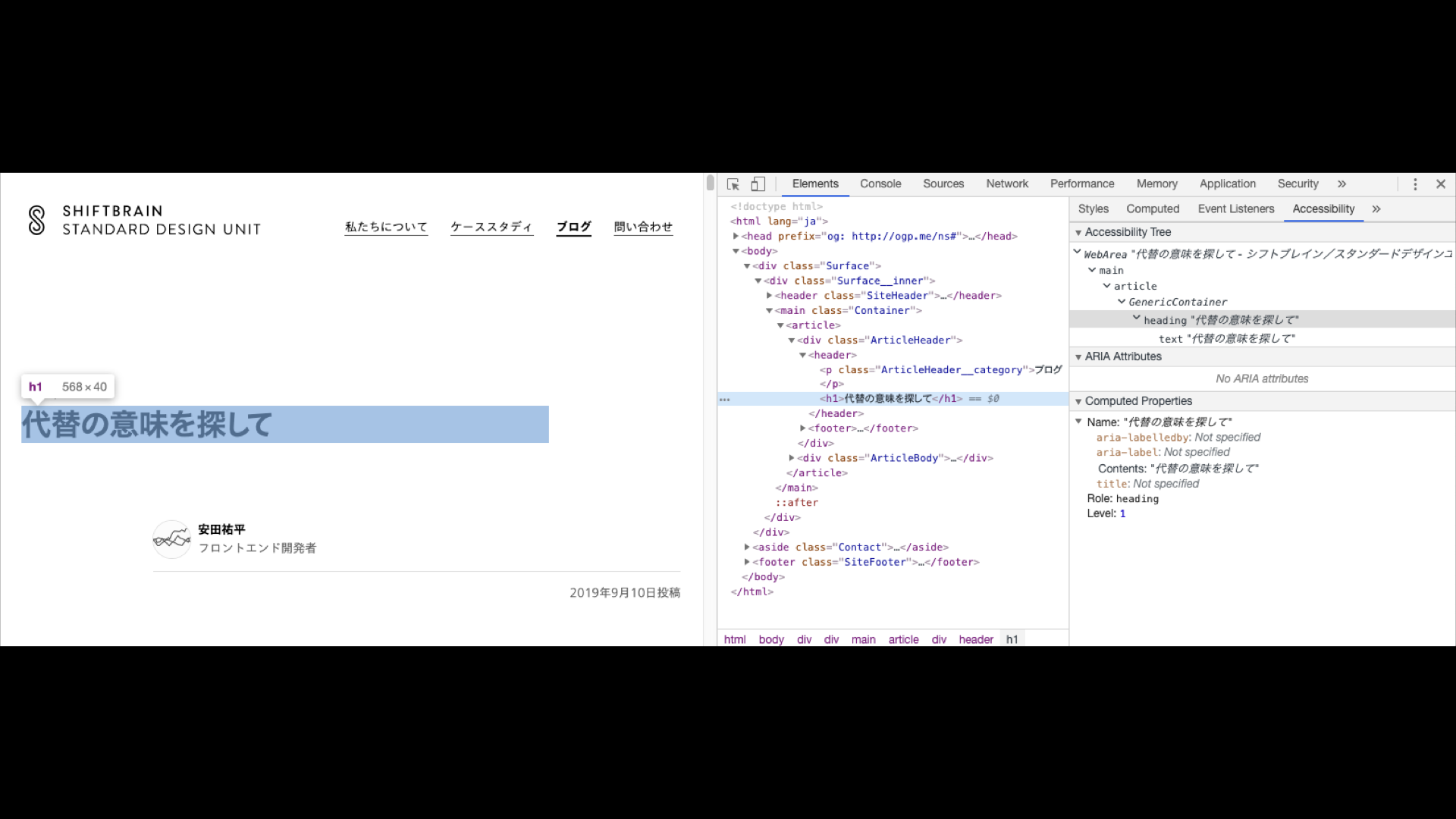
Chromeが形成したアクセシビリティツリーをDevToolsで検証しているスクリーンショット
アクセシビリティツリーは、HTMLが「WAI-ARIA」というHTMLに関連する仕様(およびブラウザの独自仕様)に基づいて解釈された結果です。
たとえば<div>要素はアクセシビリティツリーにおいては実質存在しないような扱いになっています。
HTMLにはセマンティクスと呼ばれる概念があり、これは仕様に基づいて機械が解釈可能な「意味」を指します。
HTMLにおいてもWAI-ARIAにおいても<div>要素はこの「意味」を持ちません。
代わりにmain・article・headingのようにWAI-ARIAとして意味のある要素は、HTMLから引き継がれてアクセシビリティツリーに反映されます。
アクセシビリティツリーは目に見える画面とは関係なく構築されるので、支援技術のユーザーにページの意味を伝えるためには、視覚的な表現とは別に制作者は機械にとって解釈可能な意味も表現する必要があります。
なぜこのように視覚的と機械のためとで二重に表現をしなければならないのかというと、視覚的な情報は広い層のユーザーにとってアクセシブルなものではないからです。
たとえば全盲のユーザーが、スクリーンリーダーなどを用いずに何かしらの技術によって視覚に相当する感覚を得られれば理想的ですが、今のところ現実的ではないようです。また視覚的な表現から機械がよしなに意味を解釈してくれてもよさそうですが、それも精度の問題があります。
そのためウェブアクセシビリティでは、ある情報をユーザーにとって知覚可能な別の形で代替することによって、特定の感覚器官だけに頼らず情報にアクセスできるようにするアプローチをとります。
スクリーンリーダーはあらゆる情報表現を「言葉による読み上げ」で代替します。
ウェブページから視覚的に情報を得るとき、目で文字を読むほかに、要素の形・大きさ・色・要素同士の空間的な関係性などを知覚してその意味を理解したりしていますが、スクリーンリーダーはそれらすべてを言葉として表現しなければなりません。
大きい文字がページの先頭に配置されていたりすればそれがコンテンツの見出しであるというようなことはなんとなくわかりますが、スクリーンリーダーにとってはそれだけでは他の文字との違いがわかりません。
そこで見出しを表現するための<h1>要素を利用すれば、その文字は見出しであるという意味を与えられて、スクリーンリーダーでも与えられた意味に基づいて「見出し」などと読み上げることができます。
このようなHTMLの意味とページの見た目を区別する考え方は、「文書構造」と「プレゼンテーション」を分離させるというCSSのコンセプトに関係しています。

『CSS Zen Garden』は200を超える数の非常に多様なデザインのウェブページを掲載していますが、実はすべてのページがまったく同じ構造のHTMLからできています。その中で唯一、読み込んでいるCSSの内容だけが異なっています。
見た目にはこれほどの違いがあっても、アクセシビリティツリーの内容はどのページにも違いがありません。
(正確には、CSSはアクセシビリティツリーに影響します。標準としての仕様では、display: none・visibility: hiddenが指定されている要素はアクセシビリティツリーから除外されると言及されています。加えて実装によっては、displayプロパティとしてtable以外の値を指定したtable要素がtableと見なされない。あるいは逆にdisplay: tableを指定した要素がtableと見なされる。またlist-style-type: noneを指定したol・ul要素がlistと見なされない、というような挙動の違いもあります。)
つまりHTMLは性質として、目に見える意味を表現するというよりも、制作者がどのような意味を持たせたいかを先行にして記述されます。同時にHTMLは、HTMLとして表現できる意味に基づいて記述していくしかないので、HTMLとして画面を表現することはある考え方をHTMLの世界観に基づいて捉え直すことでもあります。
そのためHTMLで表現できない意味も必然的に存在します。
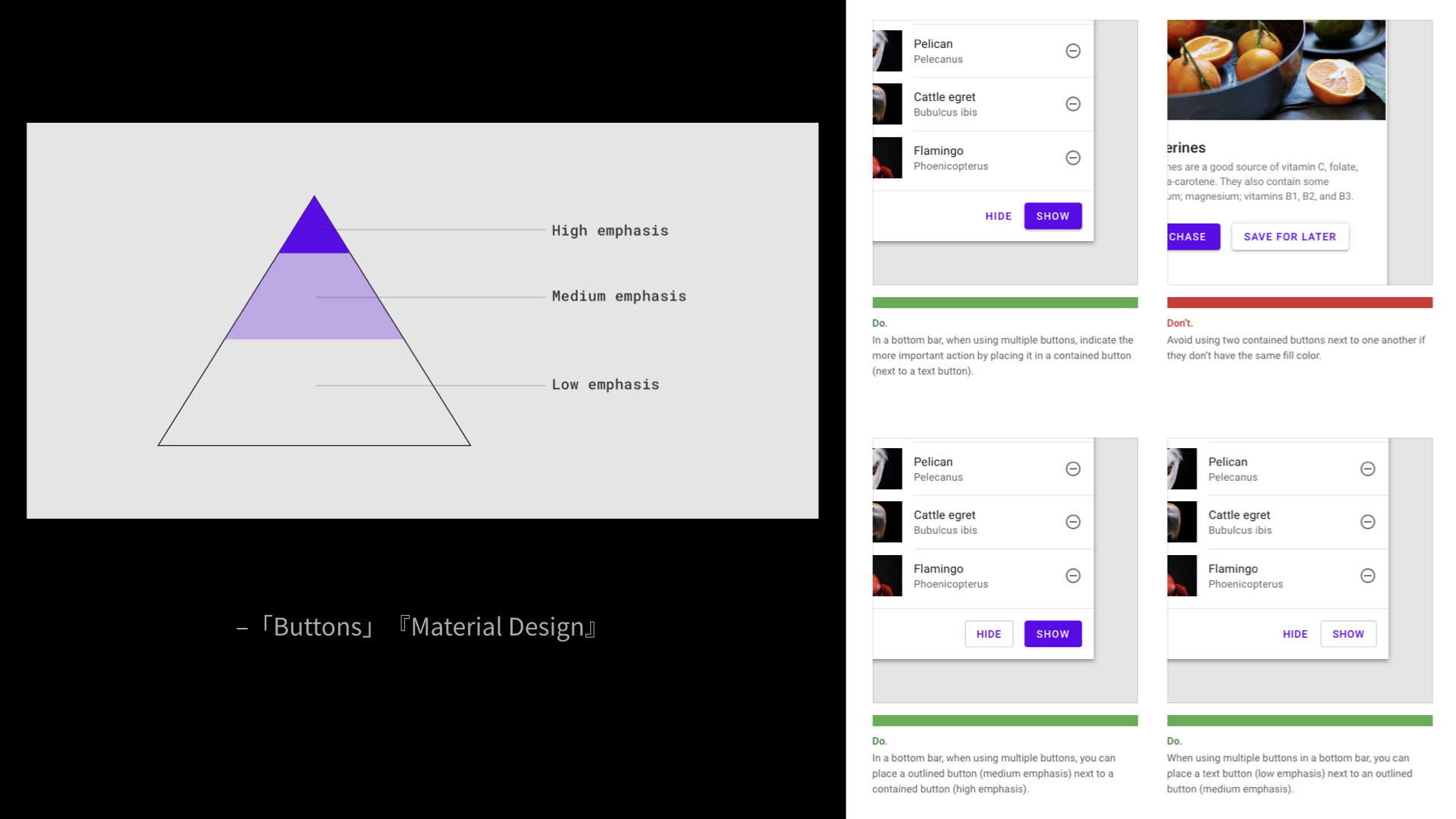
『Material Design』のガイドラインでは、ボタン同士が並ぶときに、どれが重要なボタンかを区別できるよう視覚的に優先度付けすることについて書いています。
これに従うと、隣接するボタン同士では異なる意味が視覚的には表現されるわけですが、HTMLとしてはどちらも同じマークアップになってしまいます。
これは「CSSという視覚的なレイヤーで表現されるべき意味」であると理解することもできますが、ではどのような基準をもってしてHTMLとの責務を分離させているのか明確には言い表しづらいところではあります。
また仮にHTMLで表現できる意味の数が大量に増えたとしても、画面から視覚的に感じられる意味と同じように代替として機能するかというとそうではありません。
なぜなら「見出し」のような制作者にとっては極めて基本的な要素であっても、一般のユーザーが要素に「見出し」のような名前がついているということまで知っているのは稀だからです。
ページを視覚的に理解しているユーザーであれば、要素の名前を知らずとも見た目の感じだけでなんとなく意味を理解できますが、スクリーンリーダーではUI要素の種類がそのまま読み上げられているような状態になるので、たとえば一般ユーザーに要素を識別してもらうために口頭で「パンくずリスト」とか「カルーセル」とか「アコーディオン」とか直接伝えているようなものです。
結局、すべてを言葉として表現する時点でどうしても無理が生まれてきます。
画像と代替テキストの関係性についても、本当の意味で同じ意味を伝えることは不可能です。
代替テキストは制作者側の目的に沿って記述するわけですが、もちろん同じ画像を見たときの感じ方は人によって千差万別で、制作者の意図を超えた印象を受け取られていることも普通です。どうしても特定の感覚器官からしか得られない体験があるのです。
それでも、やはり言葉にしなければ伝えられないという制約は超えられません。
だからこの代替というアプローチに向き合ったり、「HTMLとCSSのような分離し切れないもの」をどうにか分離して、完全な状態でなくても情報を伝えられるような層を作ると考える必要があります。

これについて私がもっともよい解決策だと考えているのが、HTMLとCSSとの関心を分離しやすいようにHTMLの世界観に基づいて素直に作ることです。
最終的な描画結果だけをありきにしてページをデザインしてしまうと、HTMLはそこから逆算するような形で書くしかなく、するとHTMLで表現できる文書構造として無理が出てきて、「代替のインターフェース」としてもユーザーにとって扱いづらくなります。
実装のフェーズでは普通CSSよりも先にHTMLを書きます。これはCSSが性質としてHTMLの構造に依存するため、CSSから書こうとすると不自然でやりにくいためです。CSSより先にHTMLがある方が自然に考えられます。
しかしほとんどのワークフローではデザインカンプというCSSの当てになるものが実装の前に完成しています。HTMLは後からついてくる“ついで”のような立ち位置です。
「代替」とは言葉の通り代わりのものですが、同時にある対象に見合うものです。私たちが作っているものは本当に代替たり得るのか、よく考えてみる必要があります。